From: npdoty@ischool.berkeley.edu
Date: 6/17/2016 05:34:00 PM To: friends from Berkeley and the standards/indieweb world Bcc: https://bcc.npdoty.name/
Friends,
I welcome feedback on an experimental feature, exploring ephemerality and URLs, or “ephemerurls”. Here’s the idea: sometimes I’ve posted something on my website that I want to share with some colleagues, but the thing isn’t quite finished yet. I might want to post the URL in some forum (an IRC or Slack channel, an archived mailing list, or on Twitter), but I don’t want the generally accessible URL to be permanently, publicly archived in one of those settings. That is, I want to give out a URL, but the URL should only work temporarily.
Ephemerurl is a service I’ve built and deployed on my own site. Here’s how it works. Let’s say I’ve been working on a piece of writing, a static HTML page, that I want to share just for a little while for some feedback. Maybe I’m presenting the in-progress work to a group of people at an in-person or virtual meeting and want to share a link in the group’s chatroom. Here’s a screenshot of that page, at its permanent URL:

I decide I want to share a link that will only work until 6pm this afternoon. So I change the URL, and add “/until6pm/” between “npdoty.name” and the rest of the URL. My site responds:
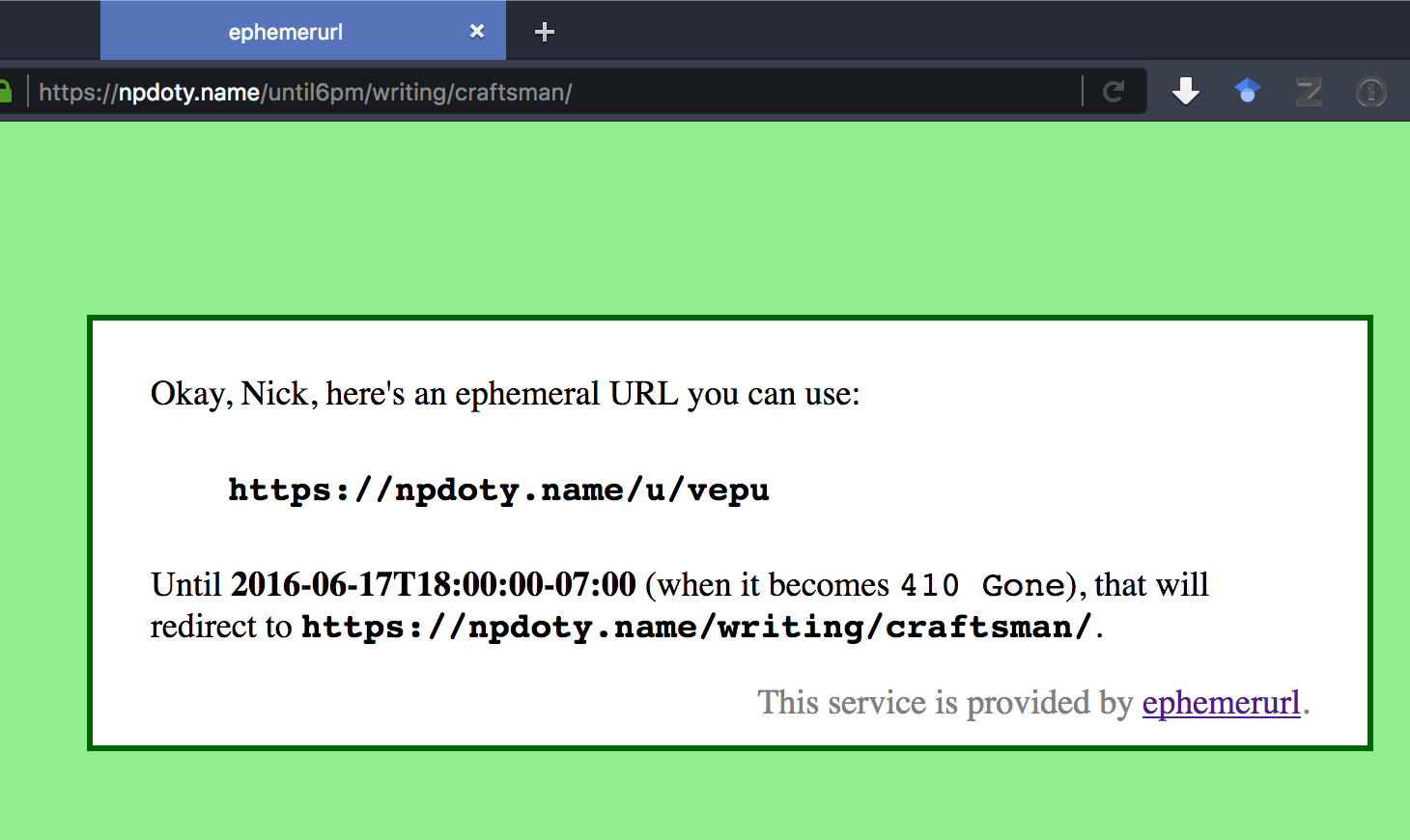
“Okay, Nick, here’s an ephemeral URL you can use” Great, I copy and paste this opaque, short URL into the chatroom: https://npdoty.name/u/vepu
Right now, that URL will redirect to the original page. (But if you don’t see this email until after 6pm my time, you’ll instead get a 410 Gone error message.) But if the chatroom logs are archived after our meeting (which they often are in groups where I work), the permanent link won’t be useful.
Of course, if you follow a URL like that, you might not realize that it’s intended to be a time-boxed URL. So the static page provides a little disclosure to you, letting you know this might not be public, and suggesting that if you share the URL, you use the same ephemeral URL that you received.
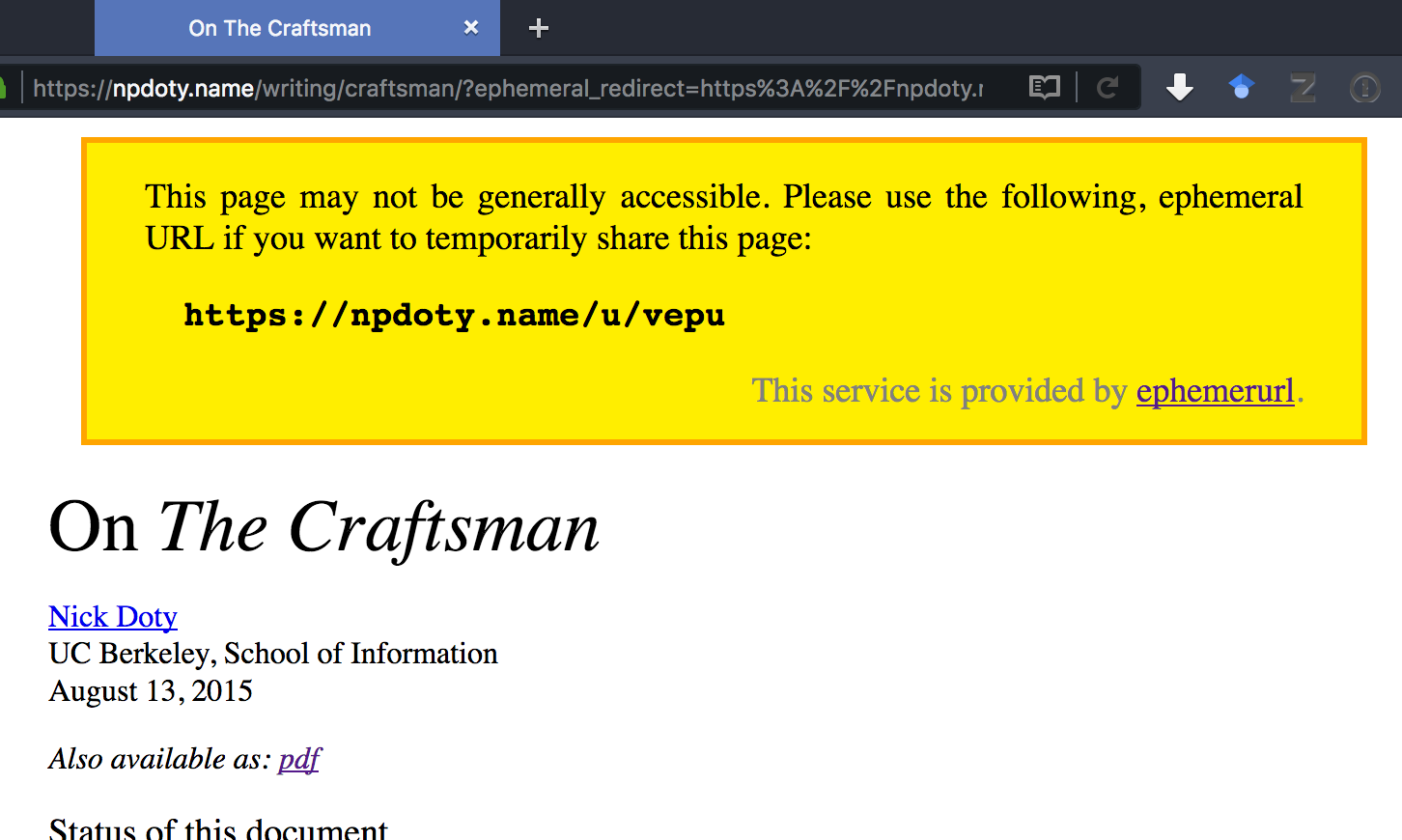
This builds on a well-known pattern. Private, “unguessable” links are a common way of building in a kind of flexible privacy/access-control into our use of the Web. They’re examples of Capability URLs. Sites will often, when accessing a private or capability URL, provide a warning to the user letting them know about the sharing norms that might apply:
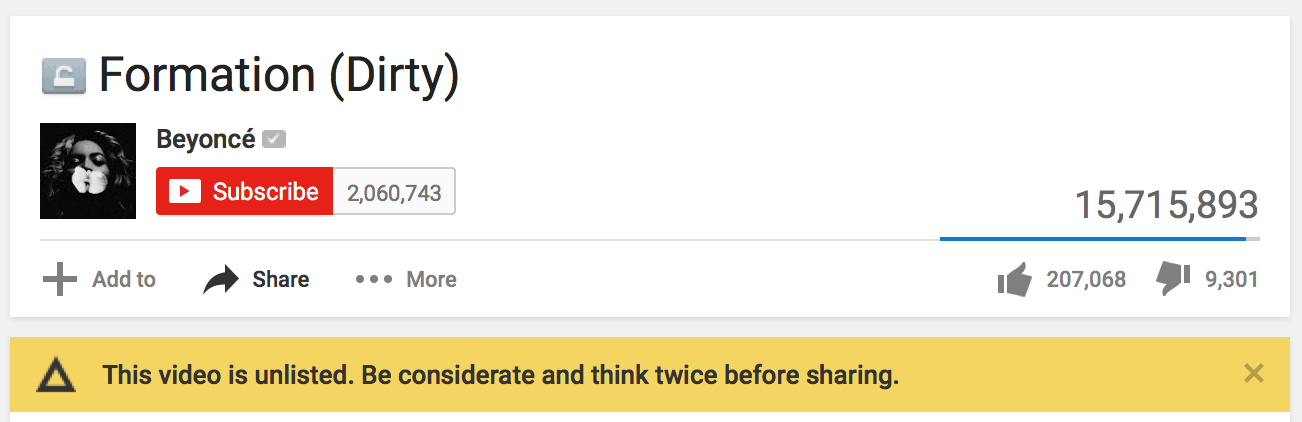
But ephemerurls also provide a specific, informal ephemerality, another increasingly popular privacy feature. It’s not effective against a malicious attacker — if I don’t want you to see my content or I don’t trust you to follow some basic norms of sharing, then this feature won’t stop you, and I’m not sure anything on the Web really could — but it uses norms and the way we often share URLs to introduce another layer of control over sharing information. Snapchat is great not because it could somehow prevent a malicious recipient from taking a screenshot, but because it introduces a norm of disappearance, which makes a certain kind of informal sharing easier.
I’d like to see the same kinds of sharing available on the Web. Disappearing URLs might be one piece, but folks are also talking about easy ways to make social media posts have a pre-determined lifetime where they’ll automatically disappear.
What do you think? Code, documentation, issues, etc. on Github.
Update: it’s been pointed out (thanks Seb, Andrew) that while I’ve built and deployed this for my own domain, it would also make sense to have a standalone service (you know, like bit.ly) that created ephemeral URLs that could work for any page on the Web without having to install some PHP. It’s like perma.cc, but the opposite. See issue #1.
Cheers,
Nick
P.S. Thanks to the Homebrew Website Club for their useful feedback when I presented some of this last month.
Labels: Web, ephemerality, privacy
From: nick@npdoty.name
Date: 5/22/2016 06:23:00 PM To: friends who host personal sites on WebFaction Cc: Eric, whose helpful guide I used in the past Bcc: https://bcc.npdoty.name/
Hiya friends using WebFaction,
Securing the Web, even our little websites, is important — to set a good example, to maintain the confidentiality and integrity of our visitors, to get the best Google search ranking. While secure Web connections had been difficult and/or costly in the past, more recently, migrating a site to HTTPS has become fairly straightforward and costs $0 a year. It may get even easier in the future, but for now, the following steps should do the trick.
Hope this helps, and please let me know if you have any issues,
Nick
P.S. Yes, other friends, I recommend WebFaction as a host; I’ve been very happy with them. Services are reasonably priced and easy to use and I can SSH into a server and install stuff. Sign up via this affiliate link and maybe I get a discount on my service or something.
P.S. And really, let me know if and when you have issues. Encrypting access to your website has gotten easier, but it needs to become much easier still, and one part of that is knowing which parts of the process prove to be the most cumbersome. I’ll make sure your feedback gets to the appropriate people who can, for realsies, make changes as necessary to standards and implementations.
Updated 27 November 2018: As of Fall 2018, WebFaction's control panel now handles installing and renewing Let's Encrypt certificates, and that functionality also breaks by default the scripts described below (you'll likely start getting email errors regarding a 404 error in loading .well-known/acme-challenge). I recommend using WebFaction's Let's Encrypt support, review their simple one-button documentation. This blog post contains the full documentation in case it still proves useful, but if you want to run these scripts, you'll also want to review this issue regarding nginx configuration.
Updated 16 July 2016: to fix the cron job command, which may not have always worked depending on environment variables
Updated 2 December 2016: to use new letsencrypt-webfaction design, which uses WebFaction's API and doesn't require emails and waiting for manual certificate installation.
One day soon I hope WebFaction will make more of these steps unnecessary, but the configuring and testing will be something you have to do manually in pretty much any case. WebFaction now supports installing and renewing certificates with Let's Encrypt just by clicking a button in the control panel! While the full instructions are still included here, you should mostly only need to follow my directions for Create a secure version of your website in the WebFaction Control Panel, Test your website over HTTPS, and Redirect your HTTP site. You should be able to complete all of this in an hour some evening.
Create a secure version of your website in the WebFaction Control Panel
Login to the Web Faction Control Panel, choose the “DOMAINS/WEBSITES” tab and then click “Websites”.
“Add new website”, one that will correspond to one of your existing websites. I suggest choosing a name like existingname-secure. Choose “Encrypted website (https)”. For Domains, testing will be easiest if you choose both your custom domain and a subdomain of yourusername.webfactional.com. (If you don’t have one of those subdomains set up, switch to the Domains tab and add it real quick.) So, for my site, I chose npdoty.name and npdoty.npd.webfactional.com.
Finally, for “Contents”, click “Re-use an existing application” and select whatever application (or multiple applications) you’re currently using for your http:// site.
Click “Save” and this step is done. This shouldn’t affect your existing site one whit.
Test to make sure your site works over HTTPS
Now you can test how your site works over HTTPS, even before you’ve created any certificates, by going to https://subdomain.yourusername.webfactional.com in your browser. Hopefully everything will load smoothly, but it’s reasonably likely that you’ll have some mixed content issues. The debug console of your browser should show them to you: that’s Apple-Option-K in Firefox or Apple-Option-J in Chrome. You may see some warnings like this, telling you that an image, a stylesheet or a script is being requested over HTTP instead of HTTPS:
Mixed Content: The page at ‘https://npdoty.name/’ was loaded over HTTPS, but requested an insecure image ‘http://example.com/blah.jpg’. This content should also be served over HTTPS.
Change these URLs so that they point to https://example.com/blah.jpg (you could also use a scheme-relative URL, like //example.com/blah.jpg) and update the files on the webserver and re-test.
Good job! Now, https://subdomain.yourusername.webfactional.com should work just fine, but https://yourcustomdomain.com shows a really scary message. You need a proper certificate.
Get a free certificate for your domain
Let’s Encrypt is a new, free, automated certificate authority from a bunch of wonderful people. But to get it to setup certificates on WebFaction is a little tricky, so we’ll use the letsencrypt-webfaction utility —- thanks will-in-wi!
SSH into the server with ssh yourusername@yourusername.webfactional.com.
To install, run this command:
GEM_HOME=$HOME/.letsencrypt_webfaction/gems RUBYLIB=$GEM_HOME/lib gem2.2 install letsencrypt_webfaction
(Run the same command to upgrade; necesary if you followed these instructions before Fall 2016.)
For convenience, you can add this as a function to make it easier to call. Edit ~/.bash_profile to include:
function letsencrypt_webfaction {
PATH=$PATH:$GEM_HOME/bin GEM_HOME=$HOME/.letsencrypt_webfaction/gems RUBYLIB=$GEM_HOME/lib ruby2.2 $HOME/.letsencrypt_webfaction/gems/bin/letsencrypt_webfaction $*
}
Now, let’s test the certificate creation process. You’ll need your email address, the domain you're getting a certificate for, the path to the files for the root of your website on the server, e.g. /home/yourusername/webapps/sitename/ and the WebFaction username and password you use to log in. Filling those in as appropriate, run this command:
letsencrypt_webfaction --letsencrypt_account_email you@example.com --domains yourcustomdomain.com --public /home/yourusername/webapps/sitename/ --username webfaction_username --password webfaction_password
If all went well, you’ll see nothing on the command line. To confirm that the certificate was created successfully, check the SSL certificates tab on the WebFaction Control Panel. ("Aren't these more properly called TLS certificates?" Yes. So it goes.) You should see a certificate listed that is valid for your domain yourcustomdomain.com; click on it and you can see the expiry date and a bunch of gobblydegook which actually is the contents of the certificate.
To actually apply that certificate, head back to the Websites tab, select the -secure version of your website from the list and in the Security section, choose the certificate you just created from the dropdown menu.
Test your website over HTTPS
This time you get to test it for real. Load https://yourcustomdomain.com in your browser. (You may need to force refresh to get the new certificate.) Hopefully it loads smoothly and without any mixed content warnings. Congrats, your site is available over HTTPS!
You are not done. You might think you are done, but if you think so, you are wrong.
Set up automatic renewal of your certificates
Certificates from Let’s Encrypt expire in no more than 90 days. (Why? There are two good reasons.) Your certificates aren’t truly set up until you’ve set them up to renew automatically. You do not want to do this manually every few months; you will forget, I promise.
Cron lets us run code on WebFaction’s server automatically on a regular schedule. If you haven’t set up a cron job before, it’s just a fancy way of editing a special text file. Run this command:
EDITOR=nano crontab -e
If you haven’t done this before, this file will be empty, and you’ll want to test it to see how it works. Paste the following line of code exactly, and then hit Ctrl-O and Ctrl-X to save and exit.
* * * * * echo "cron is running" >> $HOME/logs/user/cron.log 2>&1
This will output to that log every single minute; not a good cron job to have in general, but a handy test. Wait a few minutes and check ~/logs/user/cron.log to make sure it’s working.
Rather than including our username and password in our cron job, we'll set up a configuration file with those details. Create a file config.yml, perhaps at the location ~/le_certs. (If necessary, mkdir le_certs, touch le_certs/config.yml, nano le_certs/config.yml.) In this file, paste the following, and then customize with your details:
letsencrypt_account_email: 'you@example.com' api_url: 'https://api.webfaction.com/' username: 'webfaction_username' password: 'webfaction_password'
(Ctrl-O and Ctrl-X to save and close it.) Now, let’s edit the crontab to remove the test line and add the renewal line, being sure to fill in your domain name, the path to your website’s directory, and the path to the configuration file you just created:
0 4 15 */2 * PATH=$PATH:$GEM_HOME/bin GEM_HOME=$HOME/.letsencrypt_webfaction/gems RUBYLIB=$GEM_HOME/lib /usr/local/bin/ruby2.2 $HOME/.letsencrypt_webfaction/gems/bin/letsencrypt_webfaction --domains example.com --public /home/yourusername/webapps/sitename/ --config /home/yourusername/le_certs/config.yml >> $HOME/logs/user/cron.log 2>&1
You’ll probably want to create the line in a text editor on your computer and then copy and paste it to make sure you get all the substitutions right. Paths must be fully specified as the above; don't use ~ for your home directory. Ctrl-O and Ctrl-X to save and close it. Check with crontab -l that it looks correct. As a test to make sure the config file setup is correct, you can run the command part directly; if it works, you shouldn't see any error messages on the command line. (Copy and paste the line below, making the the same substitutions as you just did for the crontab.)
PATH=$PATH:$GEM_HOME/bin GEM_HOME=$HOME/.letsencrypt_webfaction/gems RUBYLIB=$GEM_HOME/lib /usr/local/bin/ruby2.2 $HOME/.letsencrypt_webfaction/gems/bin/letsencrypt_webfaction --domains example.com --public /home/yourusername/webapps/sitename/ --config /home/yourusername/le_certs/config.yml
With that cron job configured, you'll automatically get a new certificate at 4am on the 15th of alternating months (January, March, May, July, September, November). New certificates every two months is fine, though one day in the future we might change this to get a new certificate every few days; before then WebFaction will have taken over the renewal process anyway. Debugging cron jobs can be tricky (I've had to update the command in this post once already); I recommend adding an alert to your calendar for the day after the first time this renewal is supposed to happen, to remind yourself to confirm that it worked. If it didn't work, any error messages should be stored in the cron.log file.
Redirect your HTTP site (optional, but recommended)
Now you’re serving your website in parallel via http:// and https://. You can keep doing that for a while, but everyone who follows old links to the HTTP site won’t get the added security, so it’s best to start permanently re-directing the HTTP version to HTTPS.
WebFaction has very good documentation on how to do this, and I won’t duplicate it all here. In short, you’ll create a new static application named “redirect”, which just has a .htaccess file with, for example, the following:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www\.(.*)$ [NC]
RewriteRule ^(.*)$ https://%1/$1 [R=301,L]
RewriteCond %{HTTP:X-Forwarded-SSL} !on
RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
This particular variation will both redirect any URLs that have www to the “naked” domain and make all requests HTTPS. And in the Control Panel, make the redirect application the only one on the HTTP version of your site. You can re-use the “redirect” application for different domains.
Test to make sure it’s working! http://yourcustomdomain.com, http://www.yourcustomdomain.com, https://www.yourcustomdomain.com and https://yourcustomdomain.com should all end up at https://yourcustomdomain.com. (You may need to force refresh a couple of times.)
From: nick@npdoty.name
Date: 10/26/2014 11:11:02 AM To: Ben, Ryan, Tantek, Wendy Cc: Andrew, DKM, Seb Bcc: https://bcc.npdoty.name/
I see that work is ongoing for anti-spam proposals for the Web — if you post a response to my blog post on your own blog and send me a notification about it, how should my blog software know that you're not a spammer?
But I'm more concerned about harassment than spam. By now, it should be impossible to think about online communities without confronting directly the issue of abuse and harassment. That problem does not affect all demographic groups directly in the same way, but it effects a loss of the sense of safety that is currently the greatest threat to all of our online communities. #GamerGate should be a lesson for us. Eg. Tim Bray:
Part of me suspects there’s an upside to GamerGate: It dragged a part of the Internet that we always knew was there out into the open where it’s really hard to ignore. It’s damaged some people’s lives, but you know what? That was happening all the time, anyhow. The difference is, now we can’t not see it.
There has been useful debate about the policies that large online social networking sites are using for detecting, reporting and removing abusive content. It's not an easy algorithmic problem, it takes a psychological toll on human moderators, it puts online services into the uncomfortable position of arbiter of appropriateness of speech. Once you start down that path, it becomes increasingly difficult to distinguish between requests of various types, be it DMCA takedowns (thanks, Wendy, for chillingeffects.org); government censorship; right to be forgotten requests.
But the problem is different on the Web: not easier, not harder, just different. If I write something nasty about you on my blog, you have no control over my web server and can't take it down. As Jeff Atwood, talking about a difference between large, worldwide communities (like Facebook) and smaller, self-hosted communities (like Discourse) puts it, it's not your house:
How do we show people like this the door? You can block, you can hide, you can mute. But what you can't do is show them the door, because it's not your house. It's Facebook's house. It's their door, and the rules say the whole world has to be accommodated within the Facebook community. So mute and block and so forth are the only options available. But they are anemic, barely workable options.
I'm not sure I'm willing to accept that these options are anemic, but I want to consider the options and limitations and propose code we can write right now. It's possible that spam could be addressed in much the same way.
Self-hosted (or remote) comments are those comments and responses that are posts hosted by the commenter, on his own domain name, perhaps as part of his own blog. The IndieWeb folks have put forward a proposed standard for WebMentions so that if someone replies to my blog on their own site, I can receive a notification of that reply and, if I care to, show that response at the bottom of my post so that readers can follow the conversation. (This is like Pingback, but without the XML-RPC.) But what if those self-hosted comments are spam? What if they're full of vicious insults?
We need to update our blog software with a feature to block future mentions from these abusive domains (and handling of a block file format, more later).
The model of self-hosted comments, hosted on the commenter's domain, has some real advantages. If joeschmoe.org is writing insults about me on his blog and sending notifications via WebMention, I read the first such abusive message and then instruct my software to ignore all future notifications from joeschmoe.org. Joe might create a new domain tomorrow, start blogging from joeschmoe.net and send me another obnoxious message, but then I can block joeschmoe.net too. It costs him $10 in domain registration fees to send me a message, which is generally quite a bit more burdensome than creating an email address or a new Twitter account or spoofing a different IP address.
This isn't the same as takedown, though. Even if I "block" joeschmoe.org in my blog software so that my visitors and I don't see notifications of his insulting writing, it's still out there and people who subscribe to his blog will read it. Recent experiences with trolling and other methods of harassment have demonstrated that real harm can come not just from forcing the target to read insults or threats, but also from having them published for others to read. But this level of block functionality would be a start, and an improvement upon what we're seeing in large online social networking sites.
Here's another problem, and another couple proposals. Many people blog not from their own domain names, but as a part of a larger service, e.g. Wordpress.com or Tumblr.com. If someone posts an abusive message on harasser.wordpress.com, I can block (automatically ignore and not re-publish) all future messages from harasser.wordpress.com, but it's easy for the harasser to register a new account on a new subdomain and continue (harasser2.wordpress.com, sockpuppet1.wordpress.com, etc.). While it would be easy to block all messages from every subdomain of wordpress.com, that's probably not what I want either. It would be better if, 1) I could inform the host that this harassment is going on from some of their users and, 2) I could share lists with my friends of which domains, subdomains or accounts are abusive.
To that end, I propose the following:
That, if you maintain a Web server that hosts user-provided content from many different users, you don't mean to intentionally host abusive content and you don't want links to your server to be ignored because some of your users are posting abuse, you advertise an endpoint for reporting abuse. For example, on grouphosting.com, I would find in the <head> something like:
<link rel="abuse" href="https://grouphosting.com/abuse">I imagine that would direct to a human-readable page describing their policies for handling abusive content and a form for reporting URLs. Large hosts would probably have a CAPTCHA on that submission form. Today, for email spam/abuse, the Network Abuse Clearinghouse maintains email contact information for administrators of domains that send email, so that you can forward abusive messages to the correct source. I'm not sure a centralized directory is necessary for the Web, where it's easy to mark up metadata in our pages.
- That we explore ways to publish blocklists and subscribe to our friend's blocklists.
I'm excited to see blocktogether.org, which is a Twitter tool for blocking certain types of accounts and managing lists of blocked accounts, which can be shared. Currently under discussion is a design for subscribing to lists of blocked accounts. I spent some time working on Flaminga, a project from Cori Johnson to create a Twitter client with blocking features, at the One Web For All Hackathon. But I think blocktogether.org has a more promising design and has taken the work farther.
Publishing a list of domain names isn't technically difficult. Automated subscription would be useful, but just a standard file-format and a way to share them would go a long way. I'd like that tool in my browser too: if I click a link to a domain that my friends say hosts abusive content, then warn me before navigating to it. Shared blocklists also have the advantage of hiding abuse without requiring every individual to moderate it away. I won't even see mentions from joeschmoe.org if my friend has already dealt with his abusive behavior.
Spam blocklists are widely used today as one method of fighting email spam: maintained lists primarily of source IP addresses, that are typically distributed through an overloading of DNS. Domain names are not so disposable, so list maintainance may be more effective. We can come up with a file format for specifying inclusion/exclusion of domains, subdomains or even paths, rather than re-working the Domain Name System.
Handling, inhibiting and preventing online harassment is so important for open Web writing and reading. It's potentially a major distinguishing factor from alternative online social networking sites and could encourage adoption of personal websites and owning one's own domain. But it's also an ethical issue for the whole Web right now.
As for email spam, let's build tools for blocking domains for spam and abuse on the social Web, systems for notifying hosts about abusive content and standards for sharing blocklists. I think we can go implement and test these right now; I'd certainly appreciate hearing your thoughts, via email, your blog or at TPAC.
Nick
P.S. I'm not crazy about the proposed vouching system, because it seems fiddly to implement and because I value most highly the responses from people outside my social circles, but I'm glad we're iterating.
Also, has anyone studied the use of rhymes/alternate spellings of GamerGate on Twitter? I find an increasing usage of them among people in my Twitter feed, doing that apparently to talk about the topic without inviting the stream of antagonistic mentions they've received when they use the #GamerGate hashtag directly. Cf. the use of "grass mud horse" as an attempt to evade censorship in China, or rhyming slang in general.
Labels: Web, gamergate, spam, abuse, indieweb, harassment
From: nick@npdoty.name
Date: 9/29/2014 05:49:12 PM To: kylewm.com Bcc: https://bcc.npdoty.name/
Hi Kyle,
It's nice to think about for services that are backing-up/syndicating content from social networking sites. And comparing that disclaimer to the current situation is a useful reminder. It's great to be conscious of the potential privacy advantages but just generally the privacy implications of decentralized technologies like the Web.
Is there an etiquette about when it's fine and when it's not to publish a copy of someone's Twitter post? We may develop one, but in the meantime, I think that when someone has specifically replied to your post, it's in context to keep a copy of that post.
Nick
P.S. This is clearly mostly just a test of the webmention-sending code that I've added to this Bcc blog, but I wanted to say bravo anyway, and why not use a test post to say bravo?
Labels: web, webmention, indieweb, privacy
From: nick@npdoty.name
Date: 5/03/2014 10:12:00 PM To: Paul Ford Cc: Lissa Minkel, Seb Benthall Bcc: https://bcc.npdoty.name/
Hi Paul,
This "Great Works of Software" piece is fantastic. Of course I want to correct it, and I'm sure everyone does and I'm fairly confident that was the intention of it, and getting everyone to reflect and debate the greatest pieces of software is as worthy of an intention for a blog post (even one hosted on Medium) as any I can think of.
I don't dispute any of your five [0], but I was surprised by something: where are the Internet and the Web? Sure, the Web is a little young at 25, but it's old enough to have been declared dead a good handful of times and the Internet calls Word and Photoshop young whippersnappers. Does the Web satisfy your criteria of everyday, meaningful use? Of course. But I'm guessing that you didn't just forget the Web when writing about meaningful software. Instead, I suspect you very intentionally chose [1] to leave these out to illustrate an important point: that the Web isn't a single piece of software in the same sense that the programs you listed are.
The Web is made up of software (and hardware): web server software running on millions of machines all around the world; user agents running on every client machine we can think of (desktop, mobile, laptop, refrigerator); proxies and caching middleboxes; DNS servers; software and firmware running on routers and switches, in Internet Exchange Points and Internet Service Providers; software not included in this classification; crawlers constantly indexing and archiving Web pages; open source libraries which encrypt communications for Transport Layer Security; et cetera. But even if one had an overly-simplified view of Web architecture (and I wouldn't criticize anyone for this; this is the poor-man's Web architecture that I teach students all the time) consisting of servers and browsers, anyone would see that there's no singular piece of software involved. You mentioned the TCP/IP stack as a runner up, but there's no single TCP/IP implementation that's particularly great or important: what's important is that separate implementations of the relevant IETF standards interoperate [2]. Other listmakers included a browser (Kirschenbaum highlighted Mosaic [3]; PC World, Navigator) or you could imagine listing Apache as a canonical server (and the corresponding foundation and software development methodology), but even as important as those pieces were (and are!), alone they just don't make a difference.
As a thought experiment then, I submit a preliminary list for a Web software canon, listing not single pieces of software but systems of software, standards and people.
- Blogs (RSS/OPML/Dave Winer/Blogger/Medium): anyone can write for the world to see
- Wikis (c2/Ward Cunningham/Portland Pattern Repository/Jimmy Wales/Wikipedia/MediaWiki): we can write together, not just alone
- SSL (TLS/certificate authorities/CAB Forum/OpenSSL): we can communicate privately and do business online
- Search (Google): we can find each other, and information -- true and untrue -- about anything and everything
Non-exhaustive, of course, but I hope it's helpful for your next blog post, which I hope to see on ftrain.com. Is there something distinctive to these systems of software that are intrinsically tied up with the communities that use and develop them? Whole publics that are recursive, say [4]? I hope there are a few people out there writing books and dissertations about that. (I should really get back to writing that prospectus.)
Sincerely,
Nick
[0] Okay, I'm skeptical about Emacs -- isn't the operating system/joining of small software pieces already well-covered by Unix?
[1] By the Principle of Charity.
[2] It might be tempting, for someone who works on Web standards like I do, to claim that the Web is really just a set of interoperable standards, but that's nonsense as soon as I think about it at all. Sure, I think standards are important, but a standard without an implementation is just a bit of text somewhere. An of course, that's not hypothetical at all: standards without widespread implementation are commonplace, and bittersweet.
[3] Also, Kirschenbaum includes Hypercard in his list, with a reference to Vannevar Bush and the Memex, which I love, and it might be the closest in these lists to something that looks like the Web/hypertext but in non-networked single-piece-of-software form.
[4] Kelty, Christopher M. Two Bits: The Cultural Significance of Free Software. Duke University Press Books, 2008.
Labels: web, recursivepublics, software